KI 101
Was sind RNNs und LSTMs im Deep Learning?
Viele der beeindruckendsten Fortschritte in der Verarbeitung natürlicher Sprache und AI-Chatbots werden durch Recurrent Neural Networks (RNNs) und Long Short-Term Memory (LSTM)-Netzwerke angetrieben. RNNs und LSTMs sind spezielle neuronale Netzwerkarchitekturen, die in der Lage sind, sequenzielle Daten zu verarbeiten, Daten, bei denen die chronologische Reihenfolge wichtig ist. LSTMs sind im Wesentlichen verbesserte Versionen von RNNs, die in der Lage sind, längere Sequenzen von Daten zu interpretieren. Lassen Sie uns einen Blick darauf werfen, wie RNNs und LSTMs strukturiert sind und wie sie die Erstellung von komplexen Systemen für die Verarbeitung natürlicher Sprache ermöglichen.
Was sind Feed-Forward-Neuronale Netzwerke?
Bevor wir über die Funktionsweise von Long Short-Term Memory (LSTM) und Convolutional Neural Networks (CNN) sprechen, sollten wir das Format eines neuronalen Netzwerks im Allgemeinen besprechen.
Ein neuronales Netzwerk soll Daten untersuchen und relevante Muster lernen, damit diese Muster auf andere Daten angewendet werden können und neue Daten klassifiziert werden können. Neuronale Netzwerke sind in drei Abschnitte unterteilt: eine Eingabeschicht, eine versteckte Schicht (oder mehrere versteckte Schichten) und eine Ausgabeschicht.
Die Eingabeschicht ist das, was die Daten in das neuronale Netzwerk einliest, während die versteckten Schichten die Muster in den Daten lernen. Die versteckten Schichten im Datensatz sind mit den Eingabe- und Ausgabeschichten durch “Gewichte” und “Voreinstellungen” verbunden, die nur Annahmen darüber sind, wie die Datenpunkte miteinander verbunden sind. Diese Gewichte werden während des Trainings angepasst. Wenn das Netzwerk trainiert wird, werden die Vermutungen des Modells über die Trainingsdaten (die Ausgabewerte) mit den tatsächlichen Trainingslabels verglichen. Im Laufe des Trainings sollte das Netzwerk (hoffentlich) genauer werden, um Beziehungen zwischen Datenpunkten vorherzusagen, damit es neue Datenpunkte genau klassifizieren kann. Tiefere neuronale Netzwerke sind Netzwerke, die mehr Schichten in der Mitte/mehr versteckte Schichten haben. Je mehr versteckte Schichten und Neuronen/Knoten das Modell hat, desto besser kann es Muster in den Daten erkennen.
Reguläre, feed-forward-neuronale Netzwerke, wie die oben beschriebenen, werden oft als “dichte neuronale Netzwerke” bezeichnet. Diese dichten neuronalen Netzwerke werden mit verschiedenen Netzwerkarchitekturen kombiniert, die sich auf die Interpretation verschiedener Arten von Daten spezialisieren.
Was sind RNNs (Recurrent Neural Networks)?

Recurrent Neural Networks nehmen das allgemeine Prinzip von feed-forward-neuronalen Netzwerken und ermöglichen es ihnen, sequenzielle Daten zu verarbeiten, indem sie dem Modell ein internes Gedächtnis geben. Der “Recurrent”-Teil des RNN-Namens kommt von der Tatsache, dass die Eingabe und Ausgabe schleifen. Sobald die Ausgabe des Netzwerks produziert wird, wird die Ausgabe kopiert und als Eingabe an das Netzwerk zurückgegeben. Bei der Entscheidungsfindung werden nicht nur die aktuelle Eingabe und Ausgabe analysiert, sondern auch die vorherige Eingabe. Um es anders auszudrücken, wenn die anfängliche Eingabe für das Netzwerk X und die Ausgabe H ist, werden sowohl H als auch X1 (die nächste Eingabe in der Datenfolge) in das Netzwerk für die nächste Lernrunde eingegeben. Auf diese Weise wird der Kontext der Daten (die vorherigen Eingaben) während des Trainings des Netzwerks erhalten.
Das Ergebnis dieser Architektur ist, dass RNNs in der Lage sind, sequenzielle Daten zu verarbeiten. RNNs leiden jedoch an einigen Problemen. RNNs leiden an den verschwindenden Gradienten- und explodierenden Gradientenproblemen.
Die Länge der Sequenzen, die ein RNN interpretieren kann, ist ziemlich begrenzt, insbesondere im Vergleich zu LSTMs.
Was sind LSTMs (Long Short-Term Memory-Netzwerke)?
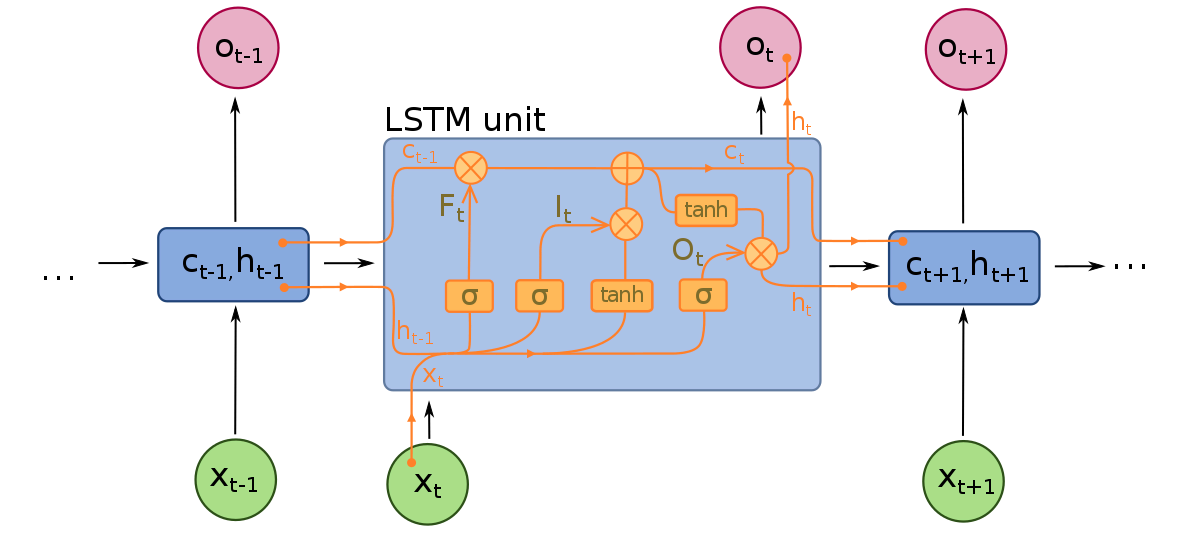
Long Short-Term Memory-Netzwerke können als Erweiterungen von RNNs betrachtet werden, die das Konzept der Erhaltung des Kontexts der Eingaben noch einmal anwenden. LSTMs wurden jedoch auf einige wichtige Weise modifiziert, die es ihnen ermöglichen, vergangene Daten mit überlegenen Methoden zu interpretieren. Die Änderungen, die an LSTMs vorgenommen wurden, befassen sich mit dem verschwindenden Gradientenproblem und ermöglichen es LSTMs, viel längere Eingabesequenzen zu berücksichtigen.

LSTM-Modelle bestehen aus drei verschiedenen Komponenten oder Gates. Es gibt ein Eingabegate, ein Ausgabegate und ein Vergessengate. Ähnlich wie RNNs berücksichtigen LSTMs Eingaben aus dem vorherigen Zeitpunkt, wenn sie das Gedächtnis des Modells und die Eingabegewichte ändern. Das Eingabegate trifft Entscheidungen darüber, welche Werte wichtig sind und durch das Modell weitergeleitet werden sollten. Eine Sigmoid-Funktion wird im Eingabegate verwendet, die Entscheidungen darüber trifft, welche Werte weitergeleitet werden sollen. Null droppt den Wert, während 1 ihn erhält. Eine TanH-Funktion wird hier auch verwendet, die entscheidet, wie wichtig die Eingabewerte für das Modell sind, von -1 bis 1.
Nachdem die aktuellen Eingaben und der Speicherzustand berücksichtigt wurden, entscheidet das Ausgabegate, welche Werte an den nächsten Zeitschritt weitergeleitet werden. Im Ausgabegate werden die Werte analysiert und mit einer Wichtigkeit zwischen -1 und 1 versehen. Dies reguliert die Daten, bevor sie an die nächste Zeitschritt-Berechnung weitergeleitet werden. Schließlich ist die Aufgabe des Vergessengates, Informationen zu löschen, die das Modell als unnötig für die Entscheidung über die Art der Eingabewerte erachtet. Das Vergessengate verwendet eine Sigmoid-Funktion auf den Werten, die Zahlen zwischen 0 (vergessen) und 1 (behalten) ausgibt.
Ein LSTM-Neuronales Netzwerk besteht aus speziellen LSTM-Schichten, die sequenzielle Wortdaten interpretieren können, und dicht verbundenen Schichten, wie oben beschrieben. Sobald die Daten durch die LSTM-Schichten verarbeitet werden, gehen sie in die dicht verbundenen Schichten über.








