موجه الهندسة
ChatGPT والهندسة السريعة المتقدمة: قيادة تطور الذكاء الاصطناعي

لعبت OpenAI دورًا محوريًا في تطوير أدوات ثورية مثل OpenAI Gym، المصممة لتدريب خوارزميات التعزيز، ونماذج GPT-n. كما يُسلَّط الضوء على DALL-E، وهو نموذج ذكاء اصطناعي يُنشئ صورًا من مُدخلات نصية. ومن بين هذه النماذج التي حظيت باهتمام كبير نموذج OpenAI. شات جي بي تي، نموذج ساطع في عالم نماذج اللغات الكبيرة.
GPT-4: الهندسة السريعة
قام ChatGPT بتحويل مشهد روبوتات الدردشة ، حيث قدم استجابات شبيهة بالبشر لمدخلات المستخدم ووسع تطبيقاته عبر المجالات - من تطوير البرامج واختبارها إلى الاتصالات التجارية ، وحتى إنشاء الشعر.
في أيدي الشركات والأفراد ، يمكن أن يكون GPT-4 ، على سبيل المثال ، بمثابة مستودع للمعرفة لا ينضب ، يتقن مواضيع تتراوح من الرياضيات وعلم الأحياء إلى الدراسات القانونية. تستعد نماذج الذكاء الاصطناعي المتطورة والتي يسهل الوصول إليها لإعادة تحديد مستقبل العمل والتعلم والإبداع.

يمكن أن تنتج النماذج التوليدية مثل GPT-4 بيانات جديدة بناءً على المدخلات الحالية. تتيح لهم هذه السمة المميزة القيام بمهام متنوعة ، بما في ذلك إنشاء النصوص والصور والموسيقى والفيديو.
في سياق نماذج ChatGPT و OpenAI ، فإن الموجه هو المدخلات التي يقدمها المستخدمون للنماذج ، وعادة ما يكون ذلك في شكل نص. تعمل الموجهات كوسيلة أساسية للتحكم في المخرجات الناتجة عن هذه النماذج ، مما يجعلها حاسمة للمحادثات الناجحة وذات الصلة.
تأثير الجودة السريعة
يعد استخدام المطالبات المحددة جيدًا هو المفتاح للانخراط في محادثات مفيدة وذات مغزى مع أنظمة الذكاء الاصطناعي. يمكن أن تؤدي المطالبات المحددة بشكل سيئ إلى إخراج غير مفيد للمستخدم وقد يؤدي إلى محتوى مضلل.
لتوضيح تأثير جودة الاستجابة السريعة، لنقارن استجابتين مختلفتين مُقدمتين إلى ChatGPT. الاستجابة الأولى، غير مُحددة بدقة وتفترض معرفة مسبقة، تُنتج استجابة قد لا تكون مفيدة للمستخدم. أما الاستجابة الثانية، فتُقدم سياقًا وأمثلة أكثر، مما يضمن استجابة أكثر صلة وفهمًا.
موجه 1: "أخبرني عن الشبكات العصبية التلافيفية."
الرد 1: "الشبكات العصبية التلافيفية (CNN) هي شبكات إدراك متعددة الطبقات تتكون من طبقات متصلة بالكامل وطبقات تجميع. يتم استخدامها بشكل شائع في مهام التعرف على الصور. تتضمن العملية تطبيق المرشحات لإدخال الصور وتقليل حجمها باستخدام طبقات التجميع ".
موجه 2: "أريد أن أتعلم المزيد عن الشبكات العصبية التلافيفية، لكن ليس لدي أي معرفة مسبقة بالشبكات العصبية الاصطناعية. هل يمكنك تقديم شرح مناسب للمبتدئين ومثال لكيفية استخدام شبكات CNN في التعرف على الصور؟"
الرد 2: "الشبكات العصبية التلافيفية (CNN) هي نوع من الشبكات العصبية المستخدمة بشكل أساسي في مهام التعرف على الصور. على عكس الشبكات العصبية الأخرى ، فإنها تستفيد من الطبقات التلافيفية وطبقات التجميع لمعالجة الصور. تخيل أن لديك صورة قطة. يمكن لشبكات CNN تحديد ميزات مختلفة في الصورة ، مثل الشعيرات والأذنين والذيل ، عن طريق تطبيق المرشحات واختزال الصورة باستخدام طبقات التجميع. تجعل هذه العملية شبكات CNN فعالة للغاية في التعرف على الأشياء في الصور ".
من خلال مقارنة الاستجابتين ، من الواضح أن موجهًا محددًا جيدًا يؤدي إلى استجابة أكثر ملاءمة وسهولة في الاستخدام. يعد التصميم والهندسة الفوريان تخصصات متنامية تهدف إلى تحسين جودة مخرجات نماذج الذكاء الاصطناعي مثل ChatGPT.
في الأقسام التالية من هذه المقالة ، سوف نتعمق في مجال المنهجيات المتقدمة التي تهدف إلى تحسين نماذج اللغات الكبيرة (LLMs) ، مثل التقنيات والتكتيكات الهندسية السريعة. يتضمن ذلك التعلم قليل اللقطات ، و ReAct ، وسلسلة الأفكار ، و RAG ، والمزيد.
تقنيات هندسية متقدمة
قبل أن نواصل، من المهم فهم مشكلة رئيسية في نماذج ماجستير القانون، تُعرف باسم "الهلوسة". في سياق نماذج ماجستير القانون، تشير "الهلوسة" إلى ميل هذه النماذج إلى توليد مخرجات قد تبدو معقولة، لكنها لا تستند إلى الواقع الفعلي أو سياق المدخلات المُعطى.
تم تسليط الضوء على هذه المشكلة بشكل صارخ في قضية محكمة حديثة حيث استخدم محامي الدفاع ChatGPT للبحث القانونياستشهدت أداة الذكاء الاصطناعي، التي تعثرت بسبب مشكلة الهلوسة، بقضايا قانونية وهمية. كان لهذا الخطأ تداعيات جسيمة، إذ تسبب في ارتباك وقوض مصداقية الإجراءات. تُذكرنا هذه الحادثة بشدة بالحاجة المُلحة لمعالجة مشكلة "الهلوسة" في أنظمة الذكاء الاصطناعي.
يهدف استكشافنا في التقنيات الهندسية السريعة إلى تحسين هذه الجوانب من ماجستير في القانون. من خلال تعزيز كفاءتها وسلامتها ، فإننا نمهد الطريق للتطبيقات المبتكرة مثل استخراج المعلومات. علاوة على ذلك ، فإنه يفتح الأبواب لدمج LLM بسلاسة مع الأدوات الخارجية ومصادر البيانات ، وتوسيع نطاق استخداماتها المحتملة.
التعلم الصفري والقليل: التحسين باستخدام الأمثلة
شكلت المحولات التوليدية مسبقة الصنع (GPT-3) نقطة تحول مهمة في تطوير نماذج الذكاء الاصطناعي التوليدية ، حيث قدمت مفهوم 'التعلم بالرصاص قليلةأحدثت هذه الطريقة نقلة نوعية بفضل قدرتها على العمل بفعالية دون الحاجة إلى ضبط دقيق شامل. يُناقش إطار عمل GPT-3 في الورقة البحثية بعنوان "نماذج اللغة هم قليلون من المتعلمين بالرصاص"حيث يوضح المؤلفون كيف يتفوق النموذج عبر حالات الاستخدام المتنوعة دون الحاجة إلى مجموعات بيانات أو تعليمات برمجية مخصصة.
على عكس الضبط الدقيق ، الذي يتطلب جهدًا مستمرًا لحل حالات الاستخدام المختلفة ، تُظهر النماذج ذات اللقطات القليلة سهولة التكيف مع مجموعة أوسع من التطبيقات. على الرغم من أن الضبط الدقيق قد يوفر حلولًا قوية في بعض الحالات ، إلا أنه قد يكون مكلفًا على نطاق واسع ، مما يجعل استخدام نماذج قليلة اللقطات نهجًا عمليًا أكثر ، لا سيما عند دمجها مع الهندسة السريعة.
تخيل أنك تحاول ترجمة الإنجليزية إلى الفرنسية. في التعلم المُختصر، ستُزود GPT-3 ببعض أمثلة الترجمة مثل "ثعلب البحر -> لؤلؤة البحر". بفضل تطوره، سيتمكن GPT-3 من مواصلة تقديم ترجمات دقيقة. أما في التعلم المُختصر، فلن تُزوده بأي أمثلة، وسيظل قادرًا على ترجمة الإنجليزية إلى الفرنسية بكفاءة.
يأتي مصطلح "التعلم المُقتضب" من فكرة أن النموذج يُعطى عددًا محدودًا من الأمثلة للتعلم منها. من المهم ملاحظة أن التعلم في هذا السياق لا يتضمن تحديث معلمات النموذج أو أوزانه، بل يؤثر على أدائه.

قليل من التعلم بالرصاص كما هو موضح في ورقة GPT-3
يأخذ التعلم بدون طلقة هذا المفهوم خطوة إلى الأمام. في التعلم الخاسر ، لا توجد أمثلة لإكمال المهمة في النموذج. من المتوقع أن يعمل النموذج جيدًا بناءً على تدريبه الأولي ، مما يجعل هذه المنهجية مثالية لسيناريوهات المجال المفتوح للإجابة على الأسئلة مثل ChatGPT.
في كثير من الحالات ، يمكن للنموذج الماهر في التعلم بدون طلقة أن يؤدي أداءً جيدًا عند تزويده بأمثلة قليلة أو حتى أمثلة أحادية اللقطة. تؤكد هذه القدرة على التبديل بين سيناريوهات التعلم الصفرية ، الفردية ، وقليلة اللقطات على قابلية التكيف للنماذج الكبيرة ، مما يعزز تطبيقاتها المحتملة عبر المجالات المختلفة.
أصبحت أساليب التعلم بدون طلقة سائدة بشكل متزايد. تتميز هذه الأساليب بقدرتها على التعرف على الأشياء غير المرئية أثناء التدريب. فيما يلي مثال عملي لموجه قليل الطلقات:
"Translate the following English phrases to French:
'sea otter' translates to 'loutre de mer'
'sky' translates to 'ciel'
'What does 'cloud' translate to in French?'"
من خلال تزويد النموذج ببعض الأمثلة ثم طرح سؤال، يمكننا توجيهه بفعالية لتوليد النتيجة المطلوبة. في هذه الحالة، من المرجح أن يترجم GPT-3 كلمة "cloud" إلى "nuage" باللغة الفرنسية بشكل صحيح.
سنتعمق في مختلف جوانب هندسة الاستجابة السريعة ودورها الأساسي في تحسين أداء النموذج أثناء الاستدلال. وسنتناول أيضًا كيفية استخدامها بفعالية لإنشاء حلول فعّالة من حيث التكلفة وقابلة للتطوير عبر مجموعة واسعة من حالات الاستخدام.
مع استمرارنا في استكشاف تعقيد تقنيات الهندسة السريعة في نماذج GPT، من المهم تسليط الضوء على منشورنا الأخير "الدليل الأساسي للهندسة السريعة في ChatGPT". يقدم هذا الدليل رؤى حول استراتيجيات توجيه نماذج الذكاء الاصطناعي بشكل فعال عبر عدد لا يحصى من حالات الاستخدام.
في مناقشاتنا السابقة، تطرقنا إلى أساليب التوجيه الأساسية لنماذج اللغات الكبيرة (LLMs)، مثل التعلم من الصفر والتعلم من خلال عدد قليل من الخطوات، بالإضافة إلى توجيه التعليمات. يُعد إتقان هذه الأساليب أمرًا بالغ الأهمية للتغلب على التحديات الأكثر تعقيدًا في هندسة التوجيه التي سنتناولها هنا.
يمكن تقييد التعلم بلقطات قليلة بسبب نافذة السياق المقيدة لمعظم LLMs. علاوة على ذلك ، بدون الضمانات المناسبة ، يمكن تضليل LLM لتقديم مخرجات ضارة محتملة. بالإضافة إلى ذلك ، تعاني العديد من النماذج من مهام التفكير أو اتباع تعليمات متعددة الخطوات.
بالنظر إلى هذه القيود ، يكمن التحدي في الاستفادة من LLMs لمعالجة المهام المعقدة. قد يكون الحل الواضح هو تطوير LLMs أكثر تقدمًا أو تحسين الموجود منها ، ولكن قد يتطلب ذلك جهدًا كبيرًا. لذا ، فإن السؤال الذي يطرح نفسه: كيف يمكننا تحسين النماذج الحالية لتحسين حل المشكلات؟
ومن المثير للاهتمام أيضًا استكشاف كيفية تفاعل هذه التقنية مع التطبيقات الإبداعية في Unite AIإتقان فن الذكاء الاصطناعي: دليل موجز لميدجورني والهندسة السريعة'الذي يصف كيف يمكن أن يؤدي اندماج الفن والذكاء الاصطناعي إلى فن مذهل.
سلسلة الفكر الموجه
يستفيد تحفيز سلسلة الأفكار من خصائص الانحدار التلقائي المتأصلة في نماذج اللغة الكبيرة (LLMs)، والتي تتميز بقدرتها الفائقة على التنبؤ بالكلمة التالية في تسلسل مُحدد. بتحفيز نموذج لتوضيح عملية تفكيره، يُحفز ذلك توليد أفكار أكثر شمولاً ومنهجية، والتي تميل إلى التوافق بشكل وثيق مع المعلومات الدقيقة. ينبع هذا التوافق من ميل النموذج لمعالجة المعلومات وتقديمها بطريقة مدروسة ومنظمة، أشبه بخبير بشري يُرشد المستمع عبر مفهوم مُعقد. غالبًا ما تكفي عبارة بسيطة مثل "أرشدني خطوة بخطوة إلى كيفية..." لتحفيز هذا الناتج الأكثر إطنابًا وتفصيلًا.
سلسلة من الأفكار مطروحة
بينما يتطلب توجيه CoT التقليدي تدريبًا مسبقًا مع عروض توضيحية، يُعد توجيه CoT المُباشر مجالًا ناشئًا. هذا النهج، الذي طرحه كوجيما وآخرون (2022)، يضيف بشكل مبتكر عبارة "لنفكر خطوة بخطوة" إلى التوجيه الأصلي.
دعنا ننشئ موجهًا متقدمًا حيث يتم تكليف ChatGPT بتلخيص النقاط الرئيسية المستفادة من أوراق البحث في مجال الذكاء الاصطناعي ومعالجة اللغة الطبيعية.
في هذا العرض التوضيحي، سنستخدم قدرة النموذج على فهم وتلخيص المعلومات المعقدة من النصوص الأكاديمية. باستخدام أسلوب التعلم السريع، دعونا نُعلّم ChatGPT تلخيص النتائج الرئيسية من أبحاث الذكاء الاصطناعي ومعالجة اللغة الطبيعية.
1. Paper Title: "Attention Is All You Need"
Key Takeaway: Introduced the transformer model, emphasizing the importance of attention mechanisms over recurrent layers for sequence transduction tasks.
2. Paper Title: "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding"
Key Takeaway: Introduced BERT, showcasing the efficacy of pre-training deep bidirectional models, thereby achieving state-of-the-art results on various NLP tasks.
Now, with the context of these examples, summarize the key findings from the following paper:
Paper Title: "Prompt Engineering in Large Language Models: An Examination"
لا يحافظ هذا الموجه على سلسلة فكرية واضحة فحسب ، بل يستخدم أيضًا نهجًا تعليميًا بسيطًا لتوجيه النموذج. إنه يرتبط بكلماتنا الرئيسية من خلال التركيز على مجالات الذكاء الاصطناعي ومعالجة اللغات الطبيعية ، وتحديداً تكليف ChatGPT بإجراء عملية معقدة تتعلق بالهندسة السريعة: تلخيص الأوراق البحثية.
موجه ReAct
تم تقديم React ، أو "Reason and Act" ، بواسطة Google في الورقة البحثية "ReAct: التآزر في التفكير والتصرف في نماذج اللغة"، وأحدث ثورة في كيفية تفاعل النماذج اللغوية مع مهمة ما ، مما دفع النموذج إلى إنشاء كل من تتبع التفكير الكلامي والإجراءات الخاصة بالمهمة بشكل ديناميكي.
تخيل طاهيًا بشريًا في المطبخ: فهو لا يكتفي بأداء سلسلة من الحركات (تقطيع الخضراوات، غلي الماء، تقليب المكونات)، بل ينخرط أيضًا في التفكير اللفظي أو الحديث الداخلي ("الآن وقد فُرمت الخضراوات، عليّ وضع القدر على الموقد"). يساعد هذا الحوار الذهني المستمر في وضع استراتيجيات للعملية، والتكيف مع التغييرات المفاجئة ("لقد نفد زيت الزيتون، سأستخدم الزبدة بدلًا منه")، وتذكر تسلسل المهام. يحاكي React هذه القدرة البشرية، مما يُمكّن النموذج من تعلم المهام الجديدة بسرعة واتخاذ قرارات فعّالة، تمامًا كما يفعل الإنسان في ظل ظروف جديدة أو غير مؤكدة.
يمكن أن يعالج React الهلوسة ، وهي مشكلة شائعة في أنظمة سلسلة الفكر (CoT). على الرغم من أن CoT تقنية فعالة ، إلا أنها تفتقر إلى القدرة على التفاعل مع العالم الخارجي ، مما قد يؤدي إلى الهلوسة الحقيقة وانتشار الخطأ. ومع ذلك ، فإن React تعوض عن ذلك من خلال التفاعل مع مصادر المعلومات الخارجية. يتيح هذا التفاعل للنظام ليس فقط التحقق من صحة منطقه ولكن أيضًا تحديث معرفته بناءً على أحدث المعلومات من العالم الخارجي.
يمكن تفسير العمل الأساسي لـ React من خلال مثيل من HotpotQA ، وهي مهمة تتطلب تفكيرًا عالي المستوى. عند تلقي سؤال ، يقسم نموذج React السؤال إلى أجزاء يمكن التحكم فيها ويضع خطة عمل. يولد النموذج تتبعًا منطقيًا (فكرًا) ويحدد الإجراء ذي الصلة. قد يقرر البحث عن معلومات حول Apple Remote على مصدر خارجي ، مثل Wikipedia (إجراء) ، ويقوم بتحديث فهمه بناءً على المعلومات التي تم الحصول عليها (الملاحظة). من خلال العديد من خطوات التفكير-العمل-الملاحظة ، يمكن لـ ReAct استرداد المعلومات لدعم منطقها مع تنقيح ما تحتاجه لاسترداده بعد ذلك.
ملاحظة:
HotpotQA هي مجموعة بيانات ، مشتقة من ويكيبيديا ، تتكون من 113 ألف زوج من الأسئلة والأجوبة مصممة لتدريب أنظمة الذكاء الاصطناعي على التفكير المعقد ، حيث تتطلب الأسئلة الاستدلال على مستندات متعددة للإجابة. على الجانب الآخر، كومونسنس يتضمن الإصدار 2.0، الذي تم إنشاؤه من خلال اللعب، 14,343 سؤالاً بنعم/لا، وهو مصمم لتحدي فهم الذكاء الاصطناعي للفطرة السليمة، حيث تم تصميم الأسئلة عمداً لتضليل نماذج الذكاء الاصطناعي.
قد تبدو العملية كما يلي:
- فكر: "أحتاج إلى البحث عن Apple Remote والأجهزة المتوافقة معها."
- اكشن: يبحث عن "الأجهزة المتوافقة مع Apple Remote" على مصدر خارجي.
- ملاحظة: للحصول على قائمة بالأجهزة المتوافقة مع Apple Remote من نتائج البحث.
- فكر: "استنادًا إلى نتائج البحث ، يمكن للعديد من الأجهزة ، بخلاف Apple Remote ، التحكم في البرنامج الذي تم تصميمه في الأصل للتفاعل معه."
والنتيجة هي عملية ديناميكية قائمة على المنطق يمكن أن تتطور بناءً على المعلومات التي تتفاعل معها ، مما يؤدي إلى استجابات أكثر دقة وموثوقية.

تصور مقارن لأربع طرق تحفيز - قياسي ، وسلسلة من الفكر ، وفعل فقط ، و ReAct ، في حل HotpotQA و AlfWorld (https://arxiv.org/pdf/2210.03629.pdf)
يعد تصميم عوامل التفاعل مهمة متخصصة ، نظرًا لقدرتها على تحقيق أهداف معقدة. على سبيل المثال ، وكيل المحادثة ، المبني على نموذج React الأساسي ، يدمج ذاكرة المحادثة لتوفير تفاعلات أكثر ثراءً. ومع ذلك ، يتم تبسيط تعقيد هذه المهمة من خلال أدوات مثل Langchain ، والتي أصبحت المعيار لتصميم هؤلاء العملاء.
موجه مؤمن بالسياق
الورقة 'موجه مخلص للسياق لنماذج اللغة الكبيرةيؤكد على أنه في حين أظهرت LLM نجاحًا كبيرًا في مهام البرمجة اللغوية العصبية القائمة على المعرفة ، فإن اعتمادها المفرط على المعرفة البارامترية يمكن أن يؤدي بهم إلى الضلال في المهام الحساسة للسياق. على سبيل المثال ، عندما يتم تدريب نموذج لغوي على حقائق قديمة ، يمكن أن ينتج إجابات غير صحيحة إذا أغفل القرائن السياقية.
تتجلى هذه المشكلة في حالات تضارب المعرفة، حيث يتضمن السياق حقائق تختلف عن المعرفة السابقة للماجستير في القانون. لنفترض مثالاً يُعطى فيه نموذج لغوي كبير (LLM)، مُجهز ببيانات قبل كأس العالم 2022، سياقًا يشير إلى فوز فرنسا بالبطولة. ومع ذلك، يواصل النموذج، معتمدًا على معرفته المُدربة مسبقًا، التأكيد على أن الفائز السابق، أي الفريق الذي فاز بكأس العالم 2018، لا يزال هو البطل. وهذا يُمثل حالة نموذجية من "تضارب المعرفة".
في جوهره، ينشأ تضارب المعرفة في نماذج التعلم العميق عندما تتعارض المعلومات الجديدة المُقدمة في السياق مع المعرفة السابقة التي دُرّب عليها النموذج. وقد يؤدي ميل النموذج إلى الاعتماد على تدريبه السابق بدلاً من السياق المُقدم حديثًا إلى نتائج غير صحيحة. من ناحية أخرى، يتمثل التذبذب في نماذج التعلم العميق في توليد استجابات قد تبدو معقولة، لكنها لا تستند إلى بيانات تدريب النموذج أو السياق المُقدم.
تظهر مشكلة أخرى عندما لا يحتوي السياق المقدم على معلومات كافية للإجابة على سؤال بدقة ، وهو الموقف المعروف باسم التنبؤ مع الامتناع عن التصويت. على سبيل المثال ، إذا تم سؤال LLM عن مؤسس Microsoft بناءً على سياق لا يوفر هذه المعلومات ، فيجب أن تمتنع بشكل مثالي عن التخمين.
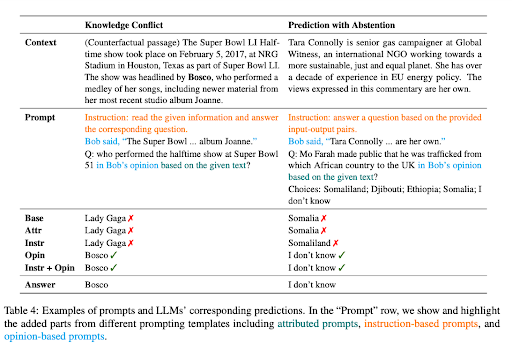
المزيد من الصراع المعرفي وقوة الامتناع عن التصويت
لتحسين دقة استجابات طلاب الماجستير في القانون في هذه السيناريوهات، اقترح الباحثون مجموعة من استراتيجيات التحفيز. تهدف هذه الاستراتيجيات إلى جعل استجابات طلاب الماجستير في القانون أكثر انسجامًا مع السياق بدلًا من الاعتماد على معرفتهم المشفرة.
إحدى هذه الاستراتيجيات هي صياغة المطالبات على شكل أسئلة مبنية على الرأي، حيث يُفسَّر السياق على أنه عبارة عن رواية للراوي، ويتعلق السؤال برأيه. يُعيد هذا النهج تركيز انتباه طالب الماجستير في القانون على السياق المُقدَّم بدلاً من اللجوء إلى معرفته السابقة.
كما تم تحديد إضافة مظاهرات معاكسة إلى المحفزات كطريقة فعالة لزيادة الإخلاص في حالات تضارب المعرفة. تقدم هذه العروض التوضيحية سيناريوهات مع حقائق خاطئة ، والتي توجه النموذج إلى إيلاء اهتمام أكبر للسياق لتقديم إجابات دقيقة.
تعليمات صقل
الضبط الدقيق للإرشادات هو مرحلة تعلم خاضعة للإشراف تستفيد من تزويد النموذج بتعليمات محددة ، على سبيل المثال ، "اشرح الفرق بين شروق الشمس وغروبها". يتم إقران التعليمات بإجابة مناسبة ، شيء على غرار ، "يشير شروق الشمس إلى اللحظة التي تظهر فيها الشمس فوق الأفق في الصباح ، بينما يشير غروب الشمس إلى النقطة التي تختفي فيها الشمس أسفل الأفق في المساء." من خلال هذه الطريقة ، يتعلم النموذج بشكل أساسي كيفية الالتزام بالتعليمات وتنفيذها.
يؤثر هذا النهج بشكل كبير على عملية تحفيز LLM ، مما يؤدي إلى تحول جذري في أسلوب التحفيز. تسمح تعليمات LLM المضبوطة بالتنفيذ الفوري للمهام التي لا تتطلب إطلاقًا ، مما يوفر أداءً سلسًا للمهام. إذا لم يتم ضبط LLM بعد ، فقد تكون هناك حاجة إلى نهج تعليمي قليل اللقطات ، مع دمج بعض الأمثلة في موجهك لتوجيه النموذج نحو الاستجابة المطلوبة.
"ضبط التعليمات باستخدام GPT-4 ′ يناقش محاولة استخدام GPT-4 لإنشاء بيانات تتبع التعليمات لضبط LLMs. استخدموا مجموعة بيانات غنية ، تضم 52,000 مدخل فريد لمتابعة التعليمات باللغتين الإنجليزية والصينية.
تلعب مجموعة البيانات دورًا محوريًا في ضبط التعليمات نماذج LLaMA، سلسلة مفتوحة المصدر من LLM ، تؤدي إلى أداء محسّن بدون طلقة في المهام الجديدة. مشاريع جديرة بالملاحظة مثل ستانفورد الألبكة استخدموا بشكل فعال ضبط Self-Instruct ، وهي طريقة فعالة لمواءمة LLM مع النوايا البشرية ، والاستفادة من البيانات التي تم إنشاؤها بواسطة نماذج المعلم المتقدمة المضبوطة بالتعليمات.

الهدف الأساسي لبحوث ضبط التعليمات هو تعزيز قدرات التعميم الصفرية والقليلة في LLM. يمكن أن توفر البيانات الإضافية وقياس النموذج رؤى قيمة. مع حجم بيانات GPT-4 الحالي عند 52K وحجم نموذج LLaMA الأساسي عند 7 مليارات معلمة ، هناك إمكانات هائلة لجمع المزيد من بيانات تتبع تعليمات GPT-4 ودمجها مع مصادر البيانات الأخرى مما يؤدي إلى تدريب نماذج LLaMA أكبر لأداء متفوق.
STaR: التمهيد المنطقي مع التفكير
تظهر إمكانات LLM بشكل خاص في مهام التفكير المعقدة مثل الرياضيات أو الإجابة على الأسئلة المنطقية. ومع ذلك ، فإن عملية تحفيز نموذج لغوي لتوليد مبررات - سلسلة من المبررات خطوة بخطوة أو "سلسلة فكرية" - لها مجموعة من التحديات. غالبًا ما يتطلب إنشاء مجموعات بيانات كبيرة للأسباب المنطقية أو تضحية في الدقة بسبب الاعتماد على استدلال قليل جدًا.
"المنطق الذي يدرس نفسه بنفسه" (نجمة) يقدم حلاً مبتكرًا لهذه التحديات. يستخدم حلقةً بسيطةً لتحسين قدرة النموذج على التفكير المنطقي باستمرار. تبدأ هذه العملية التكرارية بتوليد مُبررات للإجابة على أسئلة متعددة باستخدام بعض الأمثلة المنطقية. إذا كانت الإجابات المُولّدة غير صحيحة، يحاول النموذج مرةً أخرى توليد مُبررات، مُعطيًا هذه المرة الإجابة الصحيحة. ثم يُضبط النموذج بدقة على جميع المُبررات التي أسفرت عن إجابات صحيحة، وتُكرر العملية.

منهجية STaR ، توضح حلقة الضبط الدقيق وتوليد الأساس المنطقي على مجموعة بيانات CommonsenseQA (https://arxiv.org/pdf/2203.14465.pdf)
لتوضيح ذلك بمثال عملي ، ضع في اعتبارك السؤال "ما الذي يمكن استخدامه لحمل كلب صغير؟" مع خيارات الإجابة التي تتراوح من حوض سباحة إلى سلة. يولد نموذج STaR أساسًا منطقيًا ، يحدد أن الإجابة يجب أن تكون شيئًا قادرًا على حمل كلب صغير والهبوط على استنتاج مفاده أن السلة ، المصممة للاحتفاظ بالأشياء ، هي الإجابة الصحيحة.
يتميز نهج STaR بأنه يستفيد من قدرة نموذج اللغة على الاستدلال المسبق. فهو يستخدم عملية توليد ذاتي وصقل للأسس المنطقية، مما يُمكّنه من إعادة بناء قدراته على الاستدلال بشكل متكرر. ومع ذلك، فإن حلقة STaR محدودة. فقد يفشل النموذج في حل مسائل جديدة في مجموعة التدريب لعدم تلقيه إشارة تدريب مباشرة للمسائل التي يفشل في حلها. ولمعالجة هذه المشكلة، يُقدم STaR أسلوب الاستدلال. لكل مسألة يفشل النموذج في حلها بشكل صحيح، يُنشئ أساسًا منطقيًا جديدًا من خلال تزويد النموذج بالإجابة الصحيحة، مما يُمكّنه من الاستدلال بشكل عكسي.
لذلك ، يقف STaR كطريقة تمهيد قابلة للتطوير تسمح للنماذج بالتعلم لتوليد مبرراتها الخاصة بينما تتعلم أيضًا حل المشكلات المتزايدة الصعوبة. أظهر تطبيق STaR نتائج واعدة في المهام التي تتضمن الحساب ومسائل الكلمات الرياضية والتفكير المنطقي. في CommonsenseQA ، تحسنت STaR على كل من خط الأساس قليل اللقطات وخط الأساس الذي تم ضبطه بشكل دقيق للتنبؤ بالإجابات بشكل مباشر وأداء مماثل لنموذج أكبر بمقدار 30 ×.
موجهات السياق ذات العلامات
مفهومموجهات السياق ذات العلاماتيدور حول تزويد نموذج الذكاء الاصطناعي بطبقة إضافية من السياق عن طريق وضع علامات على معلومات معينة داخل المدخلات. تعمل هذه العلامات بشكل أساسي كعلامات إرشادية للذكاء الاصطناعي ، وتوجهه حول كيفية تفسير السياق بدقة وتوليد استجابة ذات صلة وواقعية.
تخيل أنك تُجري محادثة مع صديق حول موضوع مُعين، لنفترض "الشطرنج". تُدخل عبارة ثم تُضيف إليها مرجعًا، مثل "(المصدر: ويكيبيديا)". الآن، صديقك، وهو في هذه الحالة نموذج الذكاء الاصطناعي، يعرف تمامًا مصدر معلوماتك. يهدف هذا النهج إلى جعل استجابات الذكاء الاصطناعي أكثر موثوقية من خلال تقليل خطر الهلوسة، أو توليد حقائق مُضللة.
من الجوانب الفريدة لمطالبات السياقات المُوسومة قدرتها على تحسين "الذكاء السياقي" لنماذج الذكاء الاصطناعي. على سبيل المثال، توضح الورقة البحثية ذلك باستخدام مجموعة متنوعة من الأسئلة المُستخرجة من مصادر متعددة، مثل ملخصات مقالات ويكيبيديا حول مواضيع مختلفة، وأقسام من كتاب نُشر حديثًا. الأسئلة مُوسومة، مما يوفر لنموذج الذكاء الاصطناعي سياقًا إضافيًا حول مصدر المعلومات.
يمكن أن تكون هذه الطبقة الإضافية من السياق مفيدة بشكل لا يصدق عندما يتعلق الأمر بإنشاء استجابات ليست دقيقة فحسب، بل تلتزم أيضًا بالسياق المقدم، مما يجعل مخرجات الذكاء الاصطناعي أكثر موثوقية وجدارة بالثقة.
الخلاصة: نظرة على التقنيات الواعدة والتوجهات المستقبلية
يُظهر ChatGPT من OpenAI الإمكانات الهائلة لنماذج اللغات الكبيرة (LLMs) في معالجة المهام المعقدة بكفاءة عالية. تتيح لنا تقنيات متقدمة، مثل التعلم السريع، ومطالبات ReAct، وتسلسل الأفكار، وSTAR، تسخير هذه الإمكانات في مجموعة واسعة من التطبيقات. وبينما نتعمق في تفاصيل هذه المنهجيات، نكتشف كيف تُشكل مشهد الذكاء الاصطناعي، مُوفرةً تفاعلات أكثر ثراءً وأمانًا بين البشر والآلات.
على الرغم من التحديات مثل الصراع المعرفي ، والاعتماد المفرط على المعرفة البارامترية ، وإمكانية الهلوسة ، فقد أثبتت نماذج الذكاء الاصطناعي هذه ، مع الهندسة السريعة الصحيحة ، أنها أدوات تحويلية. يعمل ضبط التعليمات بدقة ، والتوجيه المخلص للسياق ، والتكامل مع مصادر البيانات الخارجية على زيادة تضخيم قدرتهم على التفكير والتعلم والتكيف.












